
もし「バーコードの取り違え」でシーケンスデータがぐちゃぐちゃになり、実験をやり直した経験があるなら、良いアダプターの大切さは身に染みているはずです。もしまだその経験がないなら、これはちょっとした優しい警告だと思ってください。NGSのアダプターやインデックスは、どれも同じではありません。
次世代シーケンス(NGS)のハイスループットな世界では、成功を左右するのは本当に細かなディテールです。文字通りミクロの差が結果を決めます。その中心にあるのが、きちんと作られたライブラリ。そして多くの場合、それはアダプターやインデックスで強化されたライブラリを意味します。これらは短い人工DNA配列ですが、サンプルを「読めるようにし」「仕分けできるようにし」、そして何より「信頼できるデータ」にするための重労働を担っています。
集団ゲノミクス、cfDNAの解析、あるいは古代ゲノムの研究まで、いまやUDI(Unique Dual Index)とUMI(Unique Molecular Identifier)は、現代のシーケンスワークフローに欠かせない存在になっています。名前が似ているので混同されがちですが、UDIとUMIはまったく異なる問題を解決するためのものです。この2つを組み合わせることで、研究者は「本物の変異」と「ノイズ」を見分け、多検体を安心して同時解析し、さらにコストまで最適化することができるのです。
Twist Bioscienceの考え方はとてもシンプルです。正しく設計し、徹底的にテストし、大規模運用に耐えうる形で提供する。それが、これらのツールに対する私たちのアプローチです。
感染症対策における合成核酸の役割
まずはUDIから説明しましょう。複数のサンプルをまとめてシーケンスするマルチプレックス解析では、それぞれのサンプルがどこから来たものかを識別するために、バーコード(インデックス)が必要になります。シンプルな場合は1つのインデックスでも対応できますが、ハイスループット解析でサンプルをしっかり区別したい場合(またはインデックスホッピングを避けたい場合)には、UDIが最も信頼できる方法です。
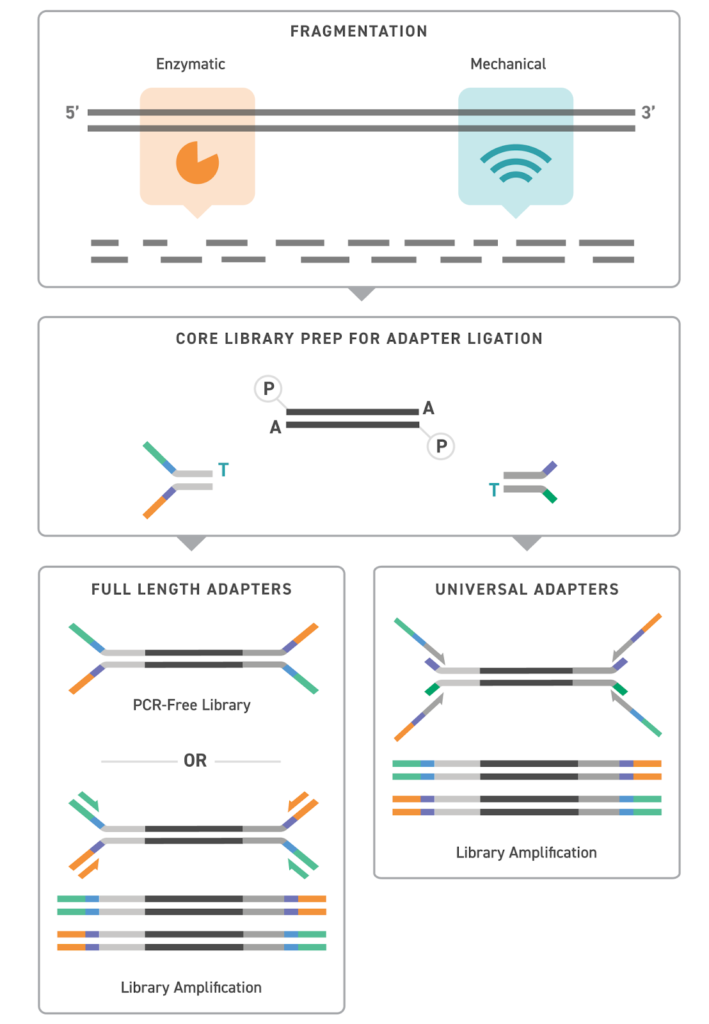
UDIは、DNA断片の両端にそれぞれ異なる2つのインデックス配列を付ける方法です(Illuminaのシーケンスでは、インデックスはP5とP7の両端に付加されます)。このように両側からラベルを付けることで、データ解析(デマルチプレックス)の際にリードが誤って別のサンプルに割り当てられる可能性を大きく減らすことができます。このような高い信頼性は、数千のサンプルを1回のハイスループットシーケンスでまとめて解析するような、集団規模のゲノム解析では特に重要です。TwistのUDIアダプターは、高い配列精度と多様性を持つように設計されており、バイオインフォマティクスの解析で多少のミスマッチを許容する場合でも、正確なサンプルの振り分けが可能になります。
🔎 際のUDIs活用例:農業分野での応用
例えば、作物や家畜、あるいは野生の魚の集団における遺伝的多様性を研究する場合、研究者は何千もの個体からサンプルをシーケンスする必要があります。これを1対1で行うのは、現実的でもなくコストも高くなります。
NGSを使えば、サンプルをまとめて処理することで、シーケンスの回数を減らすことができます。このような方法を成立させるために、研究者はUDIsを使って、それぞれの配列がどのサンプル由来かを正確に追跡します。
その結果、シーケンスの手配や管理に悩まされることなく、集団の多様性や形質の導入(イントログレッション)などの解析に集中することができます。
農業におけるNGSについて詳しくはこちらをご覧ください >>。
エムポックスウイルス由来のDNA配列は、米国外への輸出が規制対象となっているため、Twistは海外のお客様へ出荷する前に、輸出許可(エクスポートライセンス)の申請および取得を行う必要があります。合成生物学におけるバイオセキュリティの最前線で、Twist Bioscienceがどのような取り組みを行っているかについては、ぜひ詳細をご覧ください。
Twistは、ハイスループット(HT)Universal Adapter Systemにおいて、3,072種類のユニークなインデックスを提供しています—それぞれが、リードの均一な分布と配列精度の両方について実験的に検証されています。これにより、マルチプレックス解析に対する信頼性が高まり、アダプターバイアスやバーコードエラーによって失われるリードが減り、下流解析のためのより強固な基盤が得られます。
Twist BioscienceのUDIアダプター製品ラインナップの概要
- HT Universal Adapter System(12 bp):自動化に最適で、希少疾患の遺伝子パネルのような大規模研究に対応する3,072種類のユニークなインデックスを実現します。
- Universal Adapter System(10 bp):バランスの取れたインデックス設計により、がんバイオマーカー探索やその他のマルチプレックス解析における誤割り当てを低減します。
- Full Length UDI Adapter(10 bp):古代DNA解析のようなプロジェクトにおけるPCRフリー全ゲノムシーケンスに最適で、ライブラリの多様性とデータ収量を最大化します。
UMIはどうでしょうか?
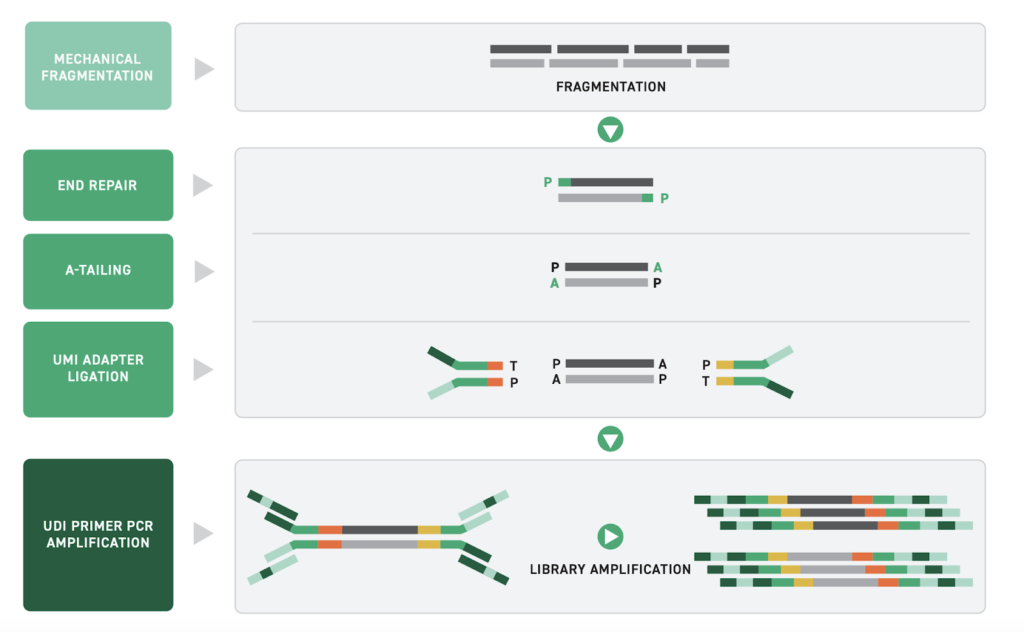
UDIが「このリードがどのサンプル由来か」を区別するのに役立つのに対して、UMIは別の問いに答えます。つまり、「この配列は元々のユニークなDNA分子に由来するものなのか、それともPCRによって生じたアーティファクトなのか?」という点です。 UMIは、増幅(PCR)の前にそれぞれの元のDNA断片に付ける短い配列で、最初に存在していた一つ一つのDNA分子を追跡できるようにするものです。特に、セルフリーDNA(cfDNA)のような難しいサンプルで低頻度の変異を検出する場合に重要です。このような場合、PCRやシーケンスのエラーによる偽陽性が信号を見えにくくしてしまうことがあります。TwistのUMIアダプターシステムは、まさにこのような用途のために設計されています。効率的なライゲーション技術と高精度なバーコード付加を組み合わせることで、まれな体細胞変異の検出や、cfDNAにおけるメチル化パターンの解析といった、非常に高い感度が求められるアプリケーションに対応します。さらに、これらのアダプターは10 bpのUDIと互換性があるため、自動化されたマルチプレックスワークフローにも対応可能で、感度を犠牲にすることなくスケール拡張ができます
🧬 際のUDIs活用例:農業分野での応用
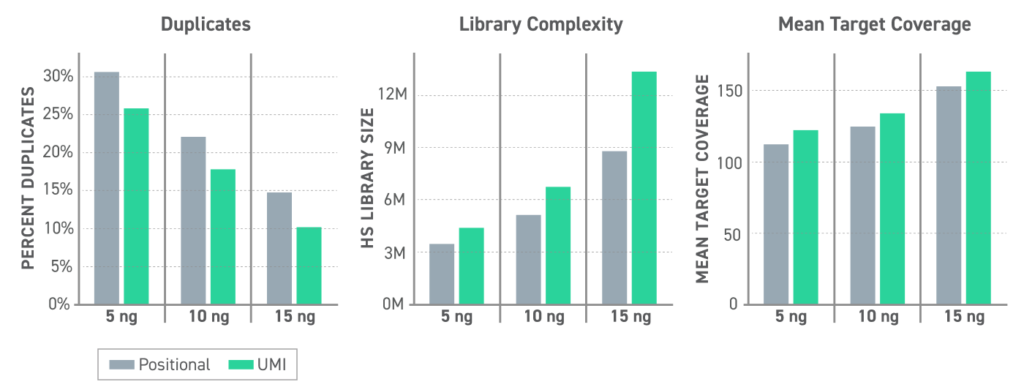
Twistは、メチル化シーケンスをサポートするために特別に設計されたUMIのセットを開発しています。これらのUMIは、Twist Methylation Detection Systemにシームレスに組み込むことができます。Twistのメチル化UMIアダプターは、正確な重複除去を可能にし、低多様性サンプルにおいて偽の重複検出を15%低減することが示されています。また、その設計は酵素的メチル化シーケンス(EM-seq)プロトコルとの互換性を確保しており、断片長を維持しつつ、利用可能なデータ量を最大化し、ターゲットカバレッジと再現性の向上につながります。そのため、高い信頼性が求められるメチル化解析において重要なツールとなります。
無理なく、賢くスケールする
NGSワークフローでよくある課題の一つが「スケール」です。1回の実験でより多くのサンプルを処理したいのに、使えるアダプターのインデックス数が限られていたり、さらに悪い場合には、性能にばらつきがあってバイアスが生じてしまうことがあります。
Twistは、性能と使いやすさのバランスを取った幅広いアダプター製品で、この課題を解決します。大規模なマルチプレックス解析に適した12 bpのHT Universal Adapter Systemでも、エピジェネティクス研究向けのTwistメチル化UMIアダプターでも、どのシステムもリード数のばらつきを抑え、バーコードの衝突を最小限にし、Tオーバーハング法に対応するよう設計されています。さらに、これらは自動化を前提としており、96ウェルや384ウェル形式が標準となっているため、作業の手間を増やすことなくスケールを拡張できます。
アダプターの質でデータを台無しにしないでください
NGSのワークフローは複雑ですが、アダプターの化学設計やバーコードの設計といった細かな要素が、結果を大きく左右します。集団規模の解析で何千ものサンプルをまとめてシーケンスする場合でも、古代DNAの解析でも、あるいはcfDNAからまれな変異を見つけ出そうとする場合でも、UDIやUMIはデータの信頼性を支える“縁の下の力持ち”です。
Twist Bioscienceは、UDIやUMIの設計において、徹底的に考え抜き、しっかりと検証を行っています。その結果、信頼性が高く、スムーズにスケールでき、ハイスループット解析にも高感度解析にも無理なく組み込めるアダプターシステムが実現されています。
次にライブラリを作製するときは、ただ手元にあるアダプターを選ぶのではなく、精度を重視し、研究成果につながるように設計されたものを選びましょう。
📊希少変異から大規模研究まで
TwistのUDIおよびUMIアダプターを使うことで、次のようなことが可能になります:
✅ 数千のサンプルをまとめて処理し、集団ゲノム研究を加速する
✅ セルフリーDNAから、がんの希少変異を高精度に検出する
✅ メチル化解析でエピジェネティックな変化を調べる
✅ データ品質を維持したまま研究のスケールを拡張する
これらの小さな合成DNAは一見目立たない存在ですが、大規模なデータを引き出し、世界を変える発見につながる重要な鍵となります
Twistのアダプターについて詳しくはこちら >>